Demonstration of BeautifulSoup to scrape data
Case study: Scraping Fry’s grocery receipt for grocery prices
import os
import re
import pandas as pd
import numpy as np
import requests
from bs4 import BeautifulSoup as bs
Load the file
To save the Fry’s receipt go to Purchases, then click on See order details. After the receipt page loads, click on View receipt. After that page loads, save that page and keep the default name which should be Fry’s Food Stores.html'. Copy this file to the same location as this script and execute the script.
pathofhtml = 'Fry’s Food Stores.html'
if os.path.exists(pathofhtml):
print("File Exists")
else:
print("File does not exist")
f = open(pathofhtml)
htmldata = f.read()
f.close()
Now, we convert the HTML data to a BeautifulSoup object. BeautifulSoup allows for a streamlined parsing of HTML data from webpages. Earlier, we have saved the Fry’s receipt as an HTML file, which we load as a BeautifulSoup object.
pagesoup = bs(htmldata)
This command creates the BeautifulSoup object, which allows for simple search functions to extract data with specific HTML tags or (as in our case) CSS tags.
The trick is to match the data with the correct tag. We right-click on the table and select Inspect.
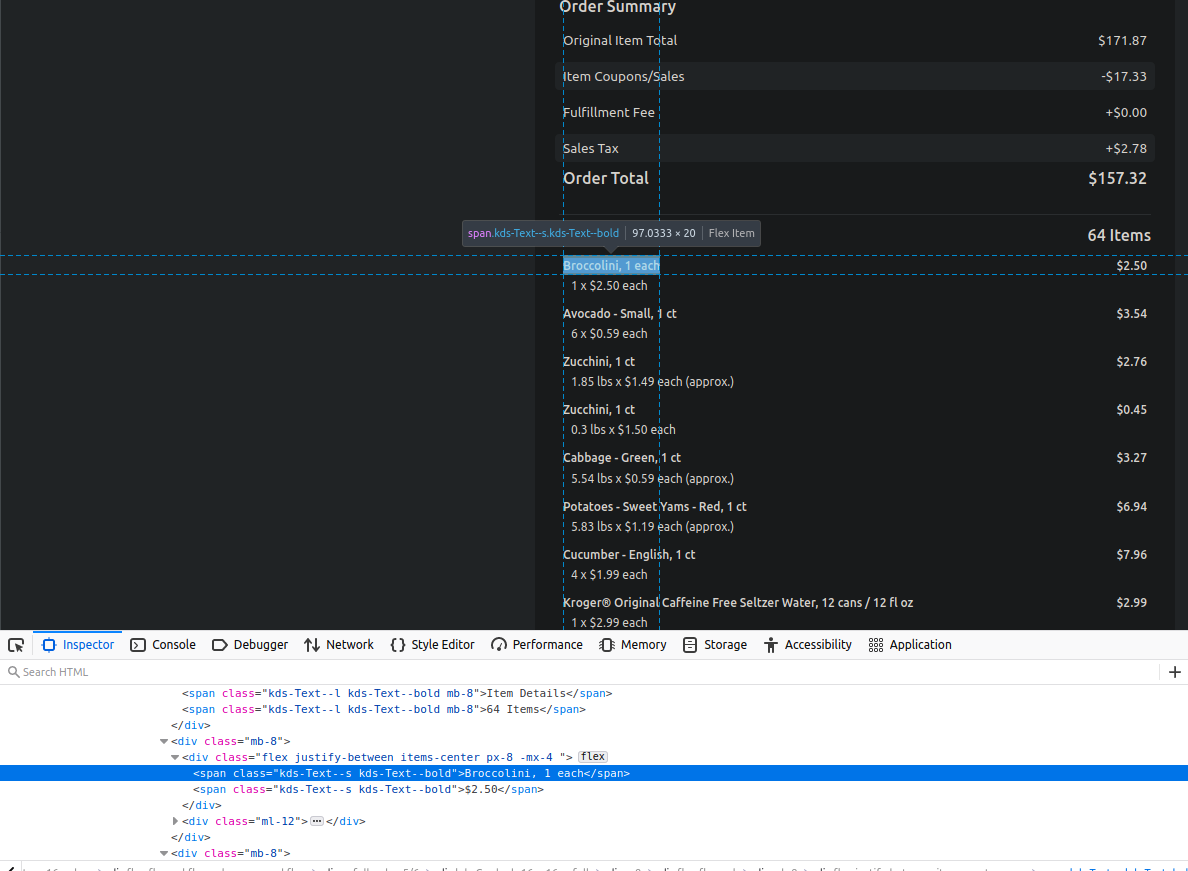
In the developer console, we see that each row of the data is contained within multiple CSS tags.
flex justify-between items-center px-8 -mx-4 contains the data in a single row,
followed by kds-Text--s kds-Text--bold which contains the data in a single column.
We first search for all HTML elements for flex justify-between items-center px-8 -mx-4. That gives
us the rows. We then iterate over the rows and scrape out the columns. There are only 2 columns per row.
So we use that knowledge to extract the item name and price: it, price = data[0].text, data[1].text.
itemlist = []
pricelist = []
for x in pagesoup.find_all(class_="flex justify-between
items-center px-8 -mx-4"):
data = x.find_all(class_="kds-Text--s kds-Text--bold")
if len(data) > 0:
it, price = data[0].text, data[1].text
itemlist.append(it)
pricelist.append(price)
df = pd.DataFrame({'item': itemlist, 'price': pricelist})
df
We pack the items and the prices into separate lists and at the end, combine the lists to generate a dataframe, which we export to a CSV file.
| item | price |
|---|---|
| Broccoli - Crowns, 1 ct | 1.29 |
| Banana, 1 ct | 1.05 |
| Potatoes - Sweet Yams - Red, 1 ct | 2.93 |
| Pear - Bosc, 1 ct | 1.31 |
| Pears - Red Anjou, 1 lb | 2.73 |
Save data to a csv file
df.to_csv('frys.csv', index=False)