Understanding Sentence Embeddings: A Practical Exploration
RAG-based chatbots and LLM are increasingly popular nowadays, relying on embeddings as their fundamental building blocks. Understanding embeddings is crucial to grasp these technologies and set up vector databases effectively. In this post, we will delve into embeddings, exploring their concept, significance, and diverse applications.
Moving on to the specifics, we’ll unravel the various methods available for performing embeddings. We’ll specifically focus on three distinct approaches, leveraging the capabilities of OpenAI’s Ada, Hugging Face Models, and SentenceTransformer to carry out the embedding process.
Understanding Embeddings: A Key to Semantic Representations
What is Embedding?
Embedding, in the realm of natural language processing (NLP), is a technique to represent words or sentences as vectors in a multi-dimensional space. This transformation allows machines to grasp semantic relationships and similarities between words or phrases, enabling them to process and understand language more effectively.
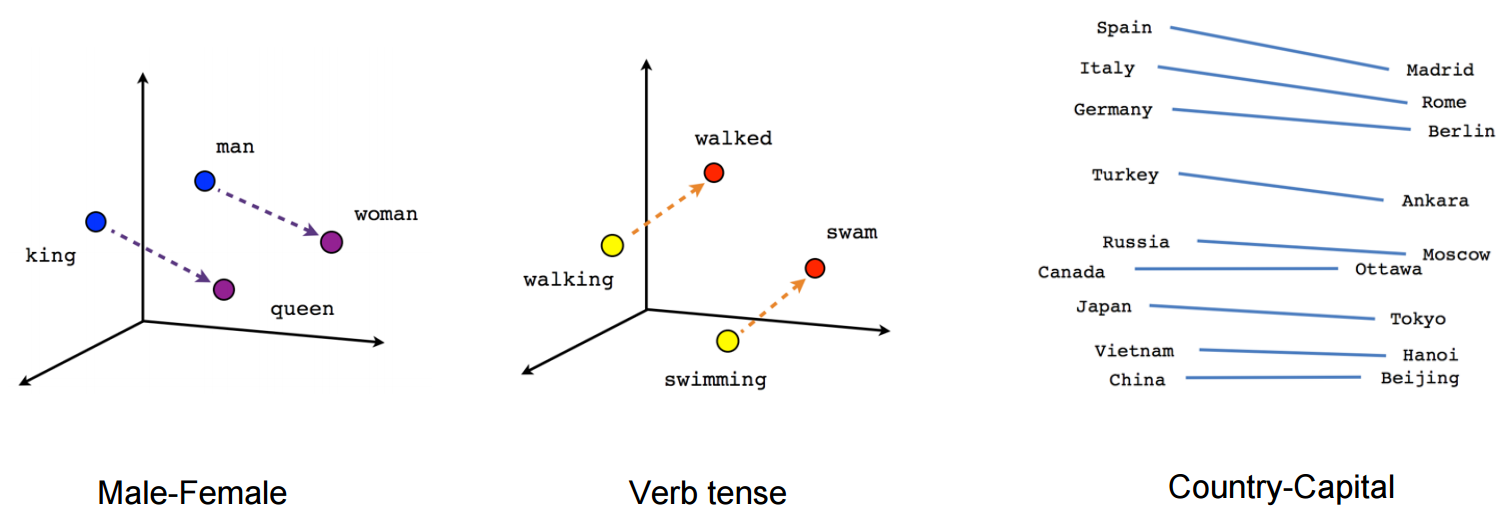
Looking at the image above, we see that the words “man”, “woman”, “king”, and “queen” are represented as vectors in a
multi-dimensional space. This representation captures the semantic relationships between these words, allowing machines
to understand the inherent meanings and similarities.
We see that the words “man” and “woman” and “king” and “queen” are spatially close, indicating their semantic proximity.
So vec(“man”) - vec(“woman”) is approximately equal to vec(“king”) - vec(“queen”).
This implies that
vec(“man”) - vec(“woman”) + vec(“queen”) ≈ vec(“king”)
Similarly, the vector embeddings for the verbs show similar semantic relationships. This is the game we used to play as children, Spain is to Madrid as Italy is to Rome, what is to Berlin? The answer is Germany. This is the same game that the embeddings are playing, but in a multi-dimensional space. The size of the space is decided by how many dimensions we choose to represent the words in. The more dimensions we use, the more accurate the representation of the words will be. But it also means that the more dimensions we use, the more computationally expensive it will be to calculate the relationships between the words.
Why is Embedding Necessary?
In NLP tasks, machines often struggle with understanding the inherent meanings of words or sentences. Traditional representations fall short in capturing nuances, leading to challenges in tasks like text classification, sentiment analysis, and information retrieval. Embedding addresses this limitation by encoding semantic relationships, providing a more nuanced and context-aware representation of language.
An Analogy: The Library of Concepts
Imagine a vast library where each book represents a unique concept or idea. To ensure efficient searches and help readers find related topics, the library needs a thoughtful organization. This is where embedding, acting as the librarian, comes into play. It assigns each concept (word or sentence) a specific location in the library, ensuring that related concepts are spatially close.
For instance, when seeking the biography of Ben Franklin, instead of searching the entire library, we would head to the biography section. Embeddings function similarly for words and sentences, grouping similar ones together in a multi-dimensional space to streamline searches. This principle is fundamental to vector databases. While the actual process may vary based on the use case, resource availability, and scaling requirements, the core idea remains consistent: group similar words in a higher-dimensional space for efficient searches.
For example, a search for “dog” in a semantic search will yield words like “pooch,” “hound,” “canine,” “pet,” etc. Expanding the search radius might reveal more words such as “animal” and “mammal.” This applies to general embeddings. When fine-tuning the embedding with conversations about our dog Burt, the semantic search will also associate “Burt” closely with the word “dog.”
Approach Merits and Demerits:
Each embedding approach comes with its set of merits and demerits.
- OpenAI’s Ada:
- Merits: Streamlined and user-friendly, suitable for various NLP tasks.
- Demerits: Potential API usage limits and associated costs.
- Hugging Face Models (bert-base-uncased):
- Merits: Versatile, widely-used, and pre-trained models available for various NLP applications.
- Demerits: Computational intensity, requiring substantial resources.
- SentenceTransformer (langchain):
- Merits: Flexibility and customization options, suitable for tailored embeddings.
- Demerits: May require specific modules or libraries, learning curve for customization.
Understanding these nuances empowers practitioners to choose the embedding approach aligning with their task requirements, computational constraints, and customization needs, contributing to the effective utilization of embeddings in NLP.
Use Cases
Spotify: Enhancing Music Recommendations Spotify leverages embeddings to enhance its music recommendation system. By embedding songs and user preferences into a high-dimensional space, Spotify can understand the nuances of user taste. This goes beyond just basic genres and artists; embeddings allow Spotify to capture intricate patterns in music preferences. As a result, users receive personalized recommendations that align with their unique musical preferences, contributing to a more satisfying and engaging user experience.
YouTube: Improving Content Recommendations YouTube, being one of the largest platforms for video content, utilizes embeddings to enhance content recommendations. By embedding videos and user interactions, YouTube’s recommendation system gains a deeper understanding of what users enjoy watching. This goes beyond simple video categories; embeddings help identify subtle connections and patterns in viewing behavior. As a result, users receive tailored content suggestions that align with their interests, keeping them engaged on the platform for longer periods.
Now, that we understand the significance of embeddings and their diverse applications, let’s delve into the practical exploration of three distinct methods for performing sentence embeddings.
Sentences to Embeddings: A Practical Exploration
Method 1: OpenAI’s Ada - A Methodical Approach
Let’s begin by setting up our environment. To interact with Ada, an API key from OpenAI is required. This key serves as our gateway to accessing Ada’s language capabilities. Once obtained, let’s initiate our exploration.
import openai
# Set your OpenAI API key
openai.api_key = "your-api-key"
With our key in place, we can choose a sentence for analysis. For this demonstration, we’ll utilize the well-known example:
# Define the input sentence
input_sentence = "The quick brown fox jumps over the lazy dog"
Now that we’ve established our groundwork, we can leverage Ada’s capabilities using OpenAI’s Embed API. This interface
allows us to obtain embeddings for our chosen sentence.
# Use OpenAI's Ada to generate embeddings
response = openai.Embed.create(
model="text-davinci-003",
data_input=input_sentence
)
# Extract embeddings from the response
ada_embeddings = response['data'][0]['embedding']
In this process, the sentence is sent to Ada through the Embed API, and the response contains the embeddings,
representing the semantic understanding of our text.
These embeddings serve as a valuable tool for various NLP applications, offering a nuanced and meaningful representation of the given text.
Method 2: Hugging Face Models - Navigating the Landscape
In our journey through sentence embeddings, the next stop brings us to the diverse and powerful world of Hugging Face models. This platform offers an array of pre-trained models, each designed to capture different facets of language understanding.
Setting the Stage
Before we embark on our exploration, let’s ensure we have the transformers library installed:
pip install transformers
Now, let’s dive into the Python code. We’ll be using the DistilBERT model, known for its efficiency and effectiveness.
from transformers import DistilBertModel, DistilBertTokenizer
# Load the DistilBERT model and tokenizer
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertModel.from_pretrained('distilbert-base-uncased')
Tokenization and Embeddings
Our next step involves tokenizing and obtaining embeddings for our sentence:
# Tokenize and obtain embeddings
tokens = tokenizer(input_sentence, return_tensors="pt")
outputs = model(**tokens)
hugging_face_embeddings = outputs.last_hidden_state.mean(dim=1).squeeze().detach().numpy()
In this code snippet, we tokenize the input sentence and pass it through the DistilBERT model. The embeddings are then obtained by calculating the mean of the last hidden state.
Hugging Face’s DistilBERT provides embeddings that encapsulate the contextual understanding of our sentence, paving the way for diverse NLP applications.
We’ve now unveiled the second method in our quest for sentence embeddings. Join us in the next section as we explore yet another avenue, enriching our understanding of the intricate world of NLP.
Method 3: Custom Embeddings with SentenceTransformer
As we continue our odyssey into the realm of embeddings, we now explore the versatility offered
by SentenceTransformer. This library equips us with the ability to create embeddings tailored to our specific needs.
Laying the Foundation
Begin by installing the langchain library, which contains the SentenceTransformerEmbeddings module:
pip install langchain
Now, let’s delve into the Python code to leverage SentenceTransformer:
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
# Load the SentenceTransformer model
sentence_transformer_model = SentenceTransformerEmbeddings()
Crafting Sentence Embeddings
With the model in place, let’s proceed to embed our sentence:
# Embed the sentence
sentence_transformer_embeddings = sentence_transformer_model.encode([input_sentence])[0]
In this code snippet, we utilize the encode method from SentenceTransformer to obtain embeddings for our input
sentence. The resulting sentence_transformer_embeddings encapsulate semantic information, providing a nuanced
representation of the sentence.
SentenceTransformer offers flexibility in embedding sentences, making it a valuable tool for various NLP tasks. As we
wrap up our exploration of different embedding methods, the final section awaits, offering a comprehensive summary of
our journey and insights into choosing the right method for specific applications. Join us as we bring together the
threads of knowledge from Ada, Hugging Face, and SentenceTransformer to enrich your understanding of sentence
embeddings.