Section 1: Introduction - Statement of the Problem
In the pharmaceutical industry, the accuracy of information displayed on medication labels is paramount. These labels typically contain critical data such as the lot number and expiry date, which are essential for ensuring patient safety and managing inventory effectively. The lot number helps trace the production batch of the medication, while the expiry date ensures that the medicine is consumed within its safe and effective usage period. Manually reading and recording this information can be labor-intensive and error-prone, especially in large-scale operations such as hospitals, pharmacies, and warehouses. Mistakes in reading lot numbers or expiry dates can lead to serious consequences, including the distribution of expired medications or the inability to perform effective recalls in case of product defects. To address these challenges, automation using machine learning techniques presents a promising solution. By training models to accurately read and extract lot numbers and expiry dates from medication labels, we can significantly reduce human error and increase operational efficiency. The core of this approach lies in using convolutional neural networks (CNNs), which are highly effective for image recognition tasks. However, obtaining a large dataset of labeled images for training these models can be a significant bottleneck. Acquiring real-world images with annotated lot numbers and expiry dates is time-consuming and often impractical due to privacy and logistical issues. This is where synthetic data generation comes into play. Synthetic data generation involves creating artificial data that resembles real-world data. In our case, we can generate images of medication labels with random lot numbers and expiry dates. This approach not only accelerates the training process but also allows us to control the variability and complexity of the dataset, making the model more robust.
In this blog post, we will guide you through the process of creating a synthetic dataset for training a CNN to extract lot numbers and expiry dates from medication labels. We will start by setting up a Google Colab environment, which provides a powerful and free platform for running Python code in the cloud. Using Google Colab, we will authenticate and interact with Google Drive to store and access our dataset. Next, we will discuss the architecture of the CNN model, comparing custom convolutional models with pre-trained models like VGG, and tools like PyTesseract for text extraction. We will also delve into hierarchical extraction techniques, which involve identifying regions of interest on the label and then extracting the relevant text. Finally, we will provide the complete code for generating synthetic labels and training the CNN model, including data augmentation techniques, k-fold cross-validation, and evaluation metrics. By the end of this blog post, you will have a comprehensive understanding of how to automate the extraction of lot numbers and expiry dates from medication labels using machine learning. Let’s embark on this journey to leverage synthetic data and machine learning for enhancing the efficiency and accuracy of medication label information extraction.
Section 2: Generate Synthetic Dataset to Speed Up Training
Creating a synthetic dataset is an efficient method to quickly generate a substantial volume of labeled data necessary for training robust machine learning models. In our project, we aim to produce a dataset comprising images of medication labels that include various lot numbers and expiry dates. This synthetic data will be instrumental in training a convolutional neural network (CNN) to accurately read and extract this essential information from real-world images.
Google Colab Setup
Google Colab is a cloud-based platform that provides free access to powerful computational resources, making it an ideal environment for our project. It supports Python and offers seamless integration with Google Drive, which we will utilize to store our synthetic dataset.
Google Drive Authentication and Setup
To begin, we need to set up Google Drive for storing and accessing our dataset. The following code will authenticate and enable interaction with Google Drive from a Google Colab notebook.
from google.colab import auth
from googleapiclient.discovery import build
from googleapiclient.http import MediaIoBaseUpload, MediaIoBaseDownload
import io
class GoogleDrive:
def __init__(self):
auth.authenticate_user()
self.drive_service = build('drive', 'v3')
def create_folder_if_not_exists(self, folder_name):
folder_id = self.get_id_by_partial_name(folder_name, mime_type='application/vnd.google-apps.folder')
if folder_id:
print(f"Folder '{folder_name}' already exists with ID: {folder_id}")
else:
folder_metadata = {
'name': folder_name,
'mimeType': 'application/vnd.google-apps.folder'
}
folder = self.drive_service.files().create(body=folder_metadata, fields='id').execute()
folder_id = folder.get('id')
print(f"Folder '{folder_name}' created with ID: {folder_id}")
return folder_id
def get_id_by_partial_name(self, partial_name, mime_type=None):
query = f"name contains '{partial_name}'"
if mime_type:
query += f" and mimeType='{mime_type}'"
results = self.drive_service.files().list(q=query, pageSize=1000, fields="files(id, name)").execute()
files = results.get('files', [])
if not files:
print(f"No matching {'folders' if mime_type == 'application/vnd.google-apps.folder' else 'files'} found.")
return None
else:
for file in files:
print(f"Name: {file['name']}, ID: {file['id']}")
return files[0]['id'] # Return the first match
def write_file_to_folder(self, folder_id, file_name, image):
image_bytes = io.BytesIO()
image.save(image_bytes, format='PNG')
image_bytes.seek(0)
file_metadata = {
'name': file_name,
'parents': [folder_id]
}
media = MediaIoBaseUpload(image_bytes, mimetype='image/png')
file = self.drive_service.files().create(body=file_metadata, media_body=media, fields='id').execute()
print(f"File '{file_name}' created with ID: {file.get('id')}")
def download_file_by_name(self, file_name, save_path):
file_id = self.get_id_by_partial_name(file_name, mime_type='image/png')
if file_id:
request = self.drive_service.files().get_media(fileId=file_id)
fh = io.BytesIO()
downloader = MediaIoBaseDownload(fh, request)
done = False
while done is False:
status, done = downloader.next_chunk()
fh.seek(0)
with open(save_path, 'wb') as f:
f.write(fh.read())
print(f"File '{file_name}' downloaded to '{save_path}'")
else:
print(f"File '{file_name}' not found in Google Drive.")
This code provides a wrapper class, GoogleDrive, that authenticates the user and offers high-level functions to read
and write to Google Drive from a Google Colab notebook.
Generating Synthetic Labels
Next, we will create another class to generate synthetic labels and store them on Google Drive. This class will be responsible for creating images with random lot numbers and expiry dates, applying transformations, and saving these images.
import random
from datetime import datetime, timedelta
from PIL import Image, ImageDraw, ImageFont
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
class LabelGenerator:
def __init__(self, font_path, use_keras_datagen=True):
self.font_path = font_path
self.use_keras_datagen = use_keras_datagen
self.google_drive = GoogleDrive()
if self.use_keras_datagen:
self.datagen = ImageDataGenerator(
rescale=1. / 255,
rotation_range=5,
shear_range=0.2,
fill_mode='nearest'
)
def generate_random_lot_number(self):
return f"LOT{random.randint(100000, 999999)}"
def generate_random_expiry_date(self, start_date, end_date):
delta = end_date - start_date
random_days = random.randint(0, delta.days)
expiry_date = start_date + timedelta(days=random_days)
return expiry_date.strftime("%d/%m/%Y")
def apply_custom_augmentation(self, image):
angle = random.uniform(-5, 5)
shear = random.uniform(-0.2, 0.2)
transformed_image = image.rotate(angle, resample=Image.BICUBIC, fillcolor=(255, 255, 255), expand=True)
transformed_image = transformed_image.transform(
transformed_image.size,
Image.AFFINE,
(1, shear, 0, shear, 1, 0),
resample=Image.BICUBIC, fillcolor=(255, 255, 255)
)
return transformed_image
def create_label_image(self, lot_number, expiry_date, image_index, folder_id, obscure_image=False):
# Create a blank image
image = Image.new('RGB', (200, 100), color=(255, 255, 255))
draw = ImageDraw.Draw(image)
# Dynamic font size selection
font_size = 20
font = ImageFont.truetype(self.font_path, font_size)
text = f"Lot: {lot_number}\nExp: {expiry_date}"
while draw.multiline_textsize(text, font=font)[0] > image.width - 20 or
draw.multiline_textsize(text, font=font)[1] > image.height - 20:
font_size -= 1
font = ImageFont.truetype(self.font_path, font_size)
# Add text to the image
draw.text((10, 10), text, font=font, fill=(0, 0, 0))
# Apply data augmentation
if self.use_keras_datagen:
image_array = np.array(image).reshape((1, 100, 200, 3))
image_array = self.datagen.flow(image_array, batch_size=1)[0].astype(np.uint8).reshape((100, 200, 3))
transformed_image = Image.fromarray(image_array)
else:
transformed_image = self.apply_custom_augmentation(image)
# Convert transformed_image to have an alpha channel
transformed_image = transformed_image.convert("RGBA")
# Create a new white image with alpha channel
final_image = Image.new('RGBA', transformed_image.size, (255, 255, 255, 255))
final_image.paste(transformed_image, (0, 0), transformed_image.split()[3]) # Use alpha channel as mask
# Obscure the image with white circles
if obscure_image:
final_image = self.obscure_image_with_white_circles(final_image)
# Convert back to RGB before saving
final_image = final_image.convert("RGB")
exp = expiry_date.replace("/", "-")
# Save the image to Google Drive
self.google_drive.write_file_to_folder(folder_id, f"image_{lot_number}_{exp}.png", final_image)
def obscure_image_with_white_circles(self, image, obscured_percentage=0.20):
draw = ImageDraw.Draw(image)
width, height = image.size
total_area = width * height
obscured_area = 0
target_area = total_area * obscured_percentage
while obscured_area < target_area:
radius = random.randint(1, 3)
diameter = radius * 2
top_left_x = random.randint(0, width - diameter)
top_left_y = random.randint(0, height - diameter)
draw.ellipse([top_left_x, top_left_y, top_left_x + diameter, top_left_y + diameter], fill=(255, 255, 255))
obscured_area += (3.14159 * (radius ** 2))
return image
def generate_labels(self, num_labels, folder_name, obscure_image=False):
folder_id = self.google_drive.create_folder_if_not_exists(folder_name)
start_date = datetime.now() + timedelta(days=365 * 2)
end_date = datetime.now() + timedelta(days=365 * 4)
labels = []
for i in range(num_labels):
lot_number = self.generate_random_lot_number()
expiry_date = self.generate_random_expiry_date(start_date, end_date)
self.create_label_image(lot_number, expiry_date, i, folder_id, obscure_image)
exp = expiry_date.replace("/", "-")
labels.append((lot_number, expiry_date, f"image_{lot_number}_{exp}.png"))
return labels
def create_dataset(self, n, folder_name, split_ratio=0.2, obscure_image=False):
labels = self.generate_labels(n, folder_name, obscure_image)
split_index = int(n * split_ratio)
train_labels = labels[split_index:]
test_labels = labels[:split_index]
print(f"Training set size: {len(train_labels)}")
print(f"Test set size: {len(test_labels)}")
return train_labels, test_labels
def load_images_and_labels(self, labels):
images = []
lot_numbers = []
expiry_dates = []
for lot_number, expiry_date, file_name in labels:
image_path = f"/content/{file_name}"
self.google_drive.download_file_by_name(file_name, image_path)
image = Image.open(image_path).resize((200, 100))
image = np.array(image)
images.append(image)
lot_numbers.append(lot_number)
expiry_dates.append(expiry_date)
return np.array(images), np.array(lot_numbers), np.array(expiry_dates)
def preprocess_labels(self, lot_numbers, expiry_dates):
# Combine lot numbers and expiry dates into a single text label
text_labels = [f"Lot: {lot}\nExp: {exp}" for lot, exp in zip(lot_numbers, expiry_dates)]
return np.array(text_labels)
Example Usage
Here’s an example of how to use these classes to generate a synthetic dataset:
# Example usage
font_path = "/usr/share/fonts/truetype/dejavu/DejaVuSans-Bold.ttf"
label_generator = LabelGenerator(font_path, use_keras_datagen=True)
# Create dataset
train_labels, test_labels = label_generator.create_dataset(1000, 'generated_labels', split_ratio=0.2,
obscure_image=True)
# Load images and labels
images, lot_numbers, expiry_dates = label_generator.load_images_and_labels(train_labels + test_labels)
# Preprocess labels
text_labels = label_generator.preprocess_labels(lot_numbers, expiry_dates)
# Normalize images
images = images / 255.0
In this example, we:
- Create an instance of the
LabelGeneratorclass, specifying the path to the font to be used for the labels. - Generate a specified number of label images and save them to a folder in Google Drive.
- Load the images and their corresponding labels from Google Drive.
- Preprocess the labels to combine the lot number and expiry date into a single text label.
- Normalize the images for training.
By using synthetic data, we can ensure that our model is trained on a diverse and comprehensive dataset, which improves its ability to generalize to real-world data. Synthetic datasets also allow us to control the variability and complexity of the data, making the model more robust and accurate in its predictions.
In the following sections, we will delve deeper into the architecture of the CNN model and discuss different strategies for text extraction from the labels. We will also explore hierarchical extraction techniques, which involve identifying regions of interest on the label and extracting the relevant text from these regions.
Here is what the synthetic images look like.

Section 3: Choosing the Right Architecture for Text Extraction
When it comes to extracting text such as lot numbers and expiry dates from images, selecting the right architecture is crucial. There are several approaches one can take, each with its own advantages and trade-offs. Below, we discuss three popular methods: custom convolutional neural networks (CNNs), pre-trained models like VGG, and OCR-based methods such as Tesseract.
Custom Convolutional Neural Networks (CNNs)
A custom CNN can be tailored specifically for the task of recognizing text in images. The strength of CNNs lies in their ability to learn spatial hierarchies of features from the input images, which is particularly useful for tasks involving visual data.
Pros:
- Flexibility to design architecture specific to the dataset and task.
- Potential for high accuracy with sufficient training data.
Cons:
- Requires a significant amount of labeled training data.
- Longer training times compared to using pre-trained models.
- Necessitates expertise in deep learning to fine-tune the architecture.
Example Architecture:
import tensorflow as tf
def create_custom_cnn(input_shape, num_classes):
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=input_shape),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(128, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(num_classes, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
return model
Pre-trained Models (e.g., VGG)
Pre-trained models like VGG have been trained on large datasets and have proven effective in a variety of image recognition tasks. By leveraging transfer learning, these models can be fine-tuned on a smaller, task-specific dataset.
Pros:
- Faster convergence due to transfer learning.
- High accuracy with less labeled data compared to training from scratch.
- Well-researched and widely used architectures.
Cons:
- Less flexibility in architecture design.
- May require significant computational resources for fine-tuning.
- Larger model size can be a constraint for deployment in resource-limited environments.
Example Usage with VGG16:
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Flatten
def create_vgg_model(input_shape, num_classes):
base_model = VGG16(weights='imagenet', include_top=False, input_shape=input_shape)
x = base_model.output
x = Flatten()(x)
x = Dense(256, activation='relu')(x)
predictions = Dense(num_classes, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
# Freeze the convolutional base
for layer in base_model.layers:
layer.trainable = False
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
return model
OCR-based Methods (e.g., Tesseract)
OCR (Optical Character Recognition) tools like Tesseract are specifically designed for extracting text from images. Tesseract is open-source and widely used for various text recognition tasks.
Pros:
- No need for extensive training data.
- Straightforward to implement and use.
- Well-suited for tasks involving printed text.
Cons:
- Performance can vary significantly based on image quality and text layout.
- Limited flexibility for recognizing highly customized or complex text patterns.
- May require pre-processing steps to improve accuracy.
Example Usage with Tesseract:
import pytesseract
from PIL import Image
def extract_text_with_tesseract(image_path):
image = Image.open(image_path)
extracted_text = pytesseract.image_to_string(image)
return extracted_text
Section 4: Choosing Tesseract for Extracting Lot Numbers and Expiry Dates
In our project to extract lot numbers and expiry dates from pharmaceutical labels, we have opted to use Tesseract OCR. Tesseract is an open-source optical character recognition (OCR) engine that can recognize text from images with high accuracy. This decision is based on several factors, including ease of use, effectiveness for our text extraction task, and the ability to handle diverse text formats and backgrounds.
Why Tesseract?
-
High Accuracy: Tesseract is known for its high accuracy in recognizing printed text. It performs well on clear and structured text like lot numbers and expiry dates found on pharmaceutical labels.
-
Ease of Use: Tesseract can be easily integrated into Python projects using the
pytesseractlibrary. This allows us to focus on other aspects of the project, such as data preprocessing and augmentation. -
Flexibility: Tesseract can handle different fonts and text sizes, making it ideal for extracting information from various label designs.
-
Open Source: Being open-source, Tesseract is free to use and has a strong community of developers and users who contribute to its improvement.
Implementation
Below, we present the code implementation for our project using Tesseract for text extraction. The process involves generating synthetic labels, uploading them to Google Drive, and then extracting the text using Tesseract.
Google Drive Integration
We use the GoogleDrive class to handle authentication and file operations with Google Drive.
Label Generation
The LabelGenerator class is responsible for generating synthetic labels, applying augmentations, and saving the images
to Google Drive.
Text Extraction and Validation
The LabelModelTrainer class uses Tesseract OCR to extract text from the images and validate it against the ground
truth labels.
import pytesseract
from PIL import Image
from difflib import SequenceMatcher
class LabelModelTrainer:
def __init__(self):
pass
def extract_text_from_image_array(self, image_array):
# Convert the numpy array image to a PIL image
image = Image.fromarray((image_array * 255).astype(np.uint8))
# Use pytesseract to extract text
extracted_text = pytesseract.image_to_string(image)
return extracted_text
def compute_accuracy_metrics(self, ground_truth, predicted):
# Compute Character Error Rate (CER)
cer = self.character_error_rate(ground_truth, predicted)
# Compute Word Error Rate (WER)
wer = self.word_error_rate(ground_truth, predicted)
return cer, wer
def character_error_rate(self, ground_truth, predicted):
# Compute the CER using Levenshtein distance
sm = SequenceMatcher(None, ground_truth, predicted)
return 1 - sm.ratio()
def word_error_rate(self, ground_truth, predicted):
# Split the text into words
ground_truth_words = ground_truth.split()
predicted_words = predicted.split()
# Compute the WER using Levenshtein distance
sm = SequenceMatcher(None, ground_truth_words, predicted_words)
return 1 - sm.ratio()
def validate_extracted_text(self, image_arrays, labels):
total_cer = 0
total_wer = 0
num_samples = len(image_arrays)
for i in range(num_samples):
extracted_text = self.extract_text_from_image_array(image_arrays[i])
ground_truth = labels[i]
cer, wer = self.compute_accuracy_metrics(ground_truth, extracted_text)
total_cer += cer
total_wer += wer
print(f"Sample {i + 1}:")
print(f"Ground Truth: {ground_truth}")
print(f"Extracted Text: {extracted_text}")
print(f"CER: {cer}, WER: {wer}")
print("-" * 50)
average_cer = total_cer / num_samples
average_wer = total_wer / num_samples
print(f"Average CER: {average_cer}")
print(f"Average WER: {average_wer}")
Running the text extraction pipeline, we can see the comparison between the ground truth (the actual text) and the
extracted text.
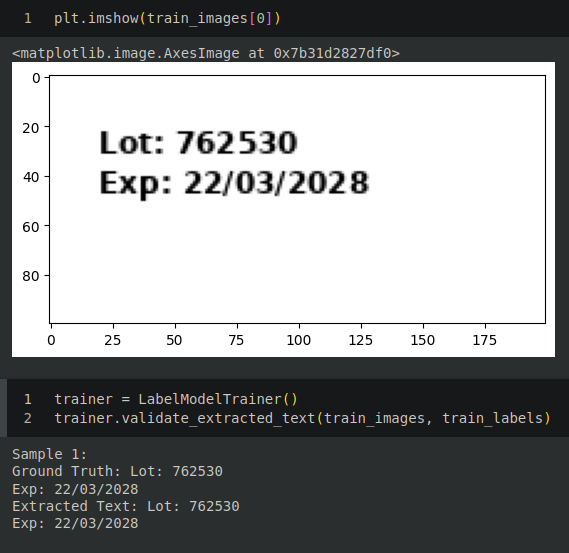
Conclusion
By using Tesseract OCR, we have created an efficient pipeline for extracting lot numbers and expiry dates from pharmaceutical labels. This approach leverages the robustness of Tesseract for text recognition, combined with custom data augmentation and Google Drive integration for managing the dataset. The results are validated using metrics such as Character Error Rate (CER) and Word Error Rate (WER), ensuring high accuracy in the text extraction process.